前言
在线策略蒸馏(On-Policy Distillation, OPD)是提升大型语言模型推理能力的有效后训练范式,通过逐 token 的密集优势信号将学生模型对齐到更强的教师模型。但标准 OPD 需要在整个训练过程中维护一个并行的教师推理服务器,基础设施开销巨大,对学术研究者极不友好。
Lightning OPD 发现了一个被忽视的关键条件——教师一致性(Teacher Consistency):SFT 阶段和 OPD 阶段必须使用同一个教师模型。违反该条件会引入不可消除的梯度偏差,导致无论在线还是离线 OPD 都收敛到次优解。在此基础上,Lightning OPD 在 SFT rollout 上一次性预计算教师的 token 级对数概率,彻底消除了对实时教师服务器的依赖。理论证明,在满足教师一致性时,离线方法与标准 OPD 共享相同的最优解,且自带防止策略漂移的隐式正则化效果。实验上,基于 Qwen3-8B-Base,Lightning OPD 在 AIME 2024 上达到 69.9%,仅需 30 GPU 小时,效率提升 4.0 倍。
背景
标准 OPD 的核心瓶颈在于:教师模型需要对学生每一步 rollout 进行评分,这意味着训练期间必须运行一个专用的多 GPU 教师服务器与训练任务并行。这对学术研究者来说成本高昂且难以复现。
一个自然的想法是将 OPD 离线化:在 SFT rollout 上预先计算教师的对数概率,然后在训练中复用。但实践中,这种朴素离线化方案无法稳定匹配标准 OPD 的性能。
作者追溯了失败根因,发现问题并非主要来自离线近似本身,而是来自一个更根本的条件——教师一致性:
- 两阶段涉及两个教师:SFT 阶段用教师 πTSFT 生成训练轨迹,OPD 阶段用教师 πTOPD 提供参考分布。这两个教师往往是不同的模型
- 现有流水线的常见错误:例如 Thinking Machines Lab 用 QwQ-32B 生成 SFT 数据,却用 Qwen3-32B 作为 OPD 教师,这种不匹配会损害性能
- 教师不一致的影响:引入不可消除的梯度偏差 GσΔ,即使增加训练时间或数据规模也无法消除,无论在线还是离线 OPD 都会收敛到次优点

框架
问题定义
给定教师模型 πT 和可训练学生模型 πθ,对于 prompt q,响应 x=(a1,…,aT) 的自回归生成为:
πθ(x∣q)=t=1∏Tπθ(at∣st)
其中 st=(q,a1,…,at−1)。SFT 初始化后的学生模型记为 πref。逐 token 的 OPD 优势函数为:
At(θ)=logπT(at∣st)−logπθ(at∣st)
当教师比学生更有信心时 At 为正,反之为负。标准 OPD 优化目标为:
Jon(θ)=Eq∼p,x∼πθ[t=1∑TAt(θ)]
Lightning OPD 将 rollout 分布固定为 πref,优化目标为:
Joff(θ)=Eq∼p,x∼πref[t=1∑TAt(θ)]
两者共享相同的优势函数,仅响应分布不同。通过重要性采样分解,∇Jon(θ)=Ex∼πref[w(x;θ)⋅∇Joff(θ)],其中 w(x;θ)=πθ(x)/πref(x),离线梯度是 w≡1 的特殊情况。
两阶段流水线
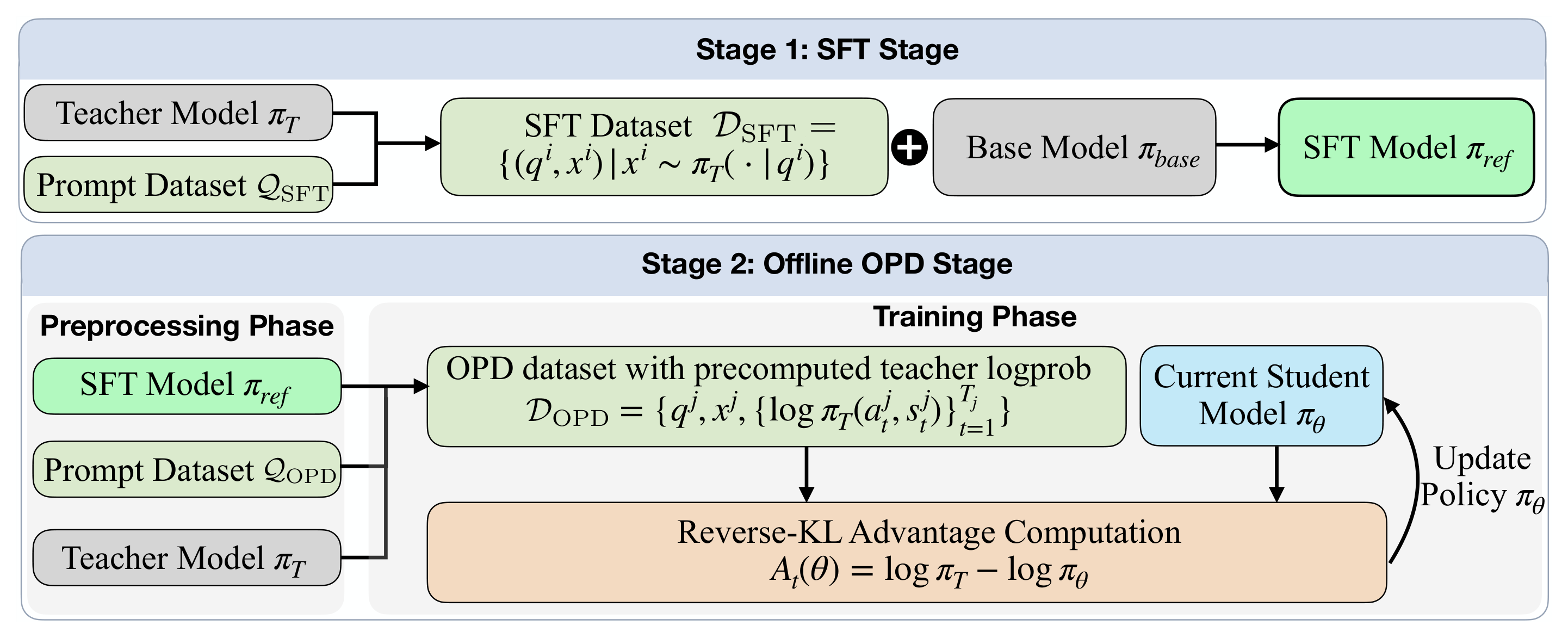
阶段一:SFT
给定基座模型 πbase、教师 πT 和 prompt 数据集 QSFT,收集教师生成的轨迹数据集:
DSFT={(qi,xi)∣xi∼πT(⋅∣qi),qi∈QSFT}
通过最大似然估计微调基座模型得到参考策略 πref:
πref=argθmaxE(q,x)∼DSFT[t=1∑Tlogπθ(at∣st)]
关键约束:DSFT 必须由 OPD 阶段的同一个教师 πT 生成,即教师一致性。
阶段二:离线 OPD
OPD 阶段分为两个子阶段。预处理阶段中,从 πref 采样 rollout 并一次性查询教师获取逐 token 对数概率,构建离线数据集:
DOPD={(qj,xj,{logπT(atj∣stj)}t=1Tj)∣xj∼πref(⋅∣qj),qj∈QOPD}
训练阶段中,学生从 πref 初始化,在 DOPD 上训练,无需教师服务器。优势计算为 At(θ)=logπT(at∣st)−logπθ(at∣st),其中教师项从 DOPD 直接读取,学生项在线计算。
理论分析
论文的理论分析基于三个标准假设:
- 优势函数二阶矩有界:Ex∼πref[(∑tAt(θ))2]≤σA2
- 支持覆盖:supp(πθ)⊆supp(πref)
- 评分函数有界:∥∇logπθ(at∣st)∥2≤G
定理(梯度差距有界):在线与离线梯度的差距满足:
∥∇Jon(θ)−∇Joff(θ)∥2≤GσAχ2(πθ∥πref)
在初始化时 πθ=πref,χ2=0,两者梯度完全一致。差距随训练步骤以 O(ηk) 速率增长。
定理(相同最优解):在教师一致性条件下,Jon 和 Joff 共享相同的稳定点集合,这些稳定点是 KL(πθ∥πT) 在参数空间中的局部最小点。
定理(隐式正则化):离线梯度可分解为 ∇Joff(θ)=∇Jon(θ)−Covπref[w,f]。协方差项随策略漂移增大,产生"恢复力"效应,自然防止策略漂移,无需显式 KL 惩罚。
定理(教师不一致的不可消除偏差):当 πTSFT=πTOPD 时,存在不可消除的梯度偏差:
∥∇Jon(θ)−∇Joff(θ)∥2≤G(σAχ2(πθ∥πref)+σΔ)
其中 GσΔ 在 πθ=πref 时仍不为零,且标准在线 OPD 同样受此偏差影响。
实验
主实验结果
在数学推理和代码生成任务上,对比 SFT baseline、标准 OPD 和 Lightning OPD:
| 模型 |
方法 |
AIME 2024 (%) |
LiveCodebench v6 (%) |
GPU Hours |
加速比 |
| Qwen3-4B-Base |
SFT |
56.7 |
31.5 |
72 |
- |
| Qwen3-4B-Base |
OPD |
65.4 |
39.3 |
72 |
- |
| Qwen3-4B-Base |
Lightning OPD |
68.1 |
40.3 |
20 |
3.6× |
| Qwen3-8B-Base |
SFT |
63.7 |
36.8 |
120 |
- |
| Qwen3-8B-Base |
OPD |
68.5 |
41.2 |
120 |
- |
| Qwen3-8B-Base |
Lightning OPD |
69.9 |
43.9 |
30 |
4.0× |
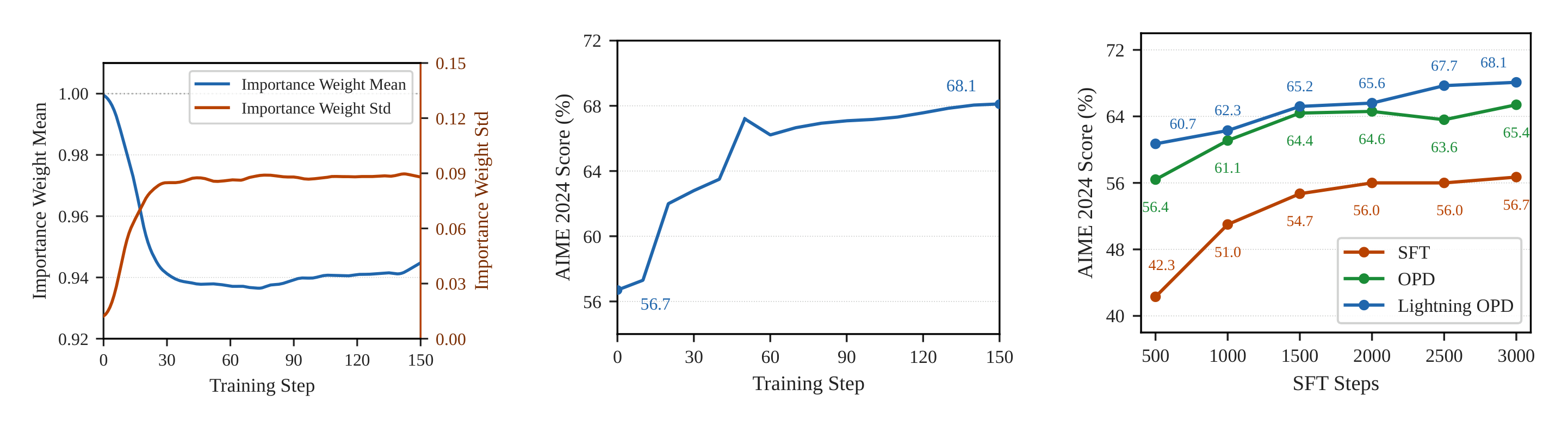
主要发现:
- Lightning OPD 在所有基准和模型规模上匹配或超越标准 OPD,同时完全消除了教师服务器需求
- 4B 规模上实现 3.6× 加速,8B 规模上实现 4.0× 加速
- 8B 模型在 AIME 2024 上达到 69.9%,仅用 30 GPU 小时
- LiveCodebench v6 上同样一致优于标准 OPD(43.9% vs 41.2%)
训练配置
SFT 阶段超参数:
| 超参数 |
4B 规模 |
8B 规模 |
| Training steps |
3000 |
3000 |
| Global batch size |
256 |
128 |
| Max sequence length |
16384 |
16384 |
| Learning rate |
8×10⁻⁵ |
8×10⁻⁵ |
| LR schedule |
cosine |
cosine |
| Warmup ratio |
0.1 |
0.1 |
| Packing |
✓ |
✓ |
| DeepSpeed stage |
ZeRO-0 |
ZeRO-1 |
OPD 阶段超参数(标准 OPD 和 Lightning OPD 共用):
| 超参数 |
4B 规模 |
8B 规模 |
| Training steps |
150 |
150 |
| Global batch size |
256 |
256 |
| Max response length |
4096 |
4096 |
| Learning rate |
2×10⁻⁶ |
2×10⁻⁶ |
| LR schedule |
constant |
constant |
| Weight decay |
0.1 |
0.1 |
| Rollout temperature |
0.8 |
0.8 |
| Rollout top-p |
1.0 |
1.0 |
| Tensor parallel size |
2 |
4 |
总结
Lightning OPD 的核心 insight 在于揭示了教师一致性这一此前被忽视的必要条件——这不仅是一个工程约束,更是 OPD 理论正确性的基础。违反该条件引入的梯度偏差是不可消除的,这解释了为什么许多现有 OPD 流水线即使投入更多计算也难以进一步提升。
局限方面,该方法严格要求 SFT 和 OPD 使用同一教师,这在实践中可能限制 SFT 数据的来源选择(不能随意使用最高质量的公开 SFT 数据集)。此外,离线近似依赖于学生策略不会大幅偏离 SFT 初始化这一经验观察,对于极长时间的训练场景可能需要进一步验证。