Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
1. 前言
NVIDIA 发布了 Nemotron 3 Super,一个 120B 总参数、12B 激活参数的混合 Mamba-Attention Mixture-of-Experts 模型。这个模型的核心亮点在于三个方面:一是首次采用 NVFP4 低精度格式进行预训练,展示了在 FP4 精度下稳定训练大模型的可行性;二是提出了 LatentMoE 架构,通过在低维隐空间中执行路由和专家计算,同时提升 accuracy per FLOP 和 accuracy per parameter;三是集成了 Multi-Token Prediction (MTP) 层,通过共享权重的推测解码在不需要外部 draft 模型的情况下加速推理。
模型在 25 万亿 token 上完成预训练(分两阶段:80% 多样性数据 + 20% 高质量数据),经 SFT 和 RL 后训练后,支持 100 万上下文长度。在 8k 输入 / 64k 输出场景下,推理吞吐量分别达到 GPT-OSS-120B 的 2.2 倍和 Qwen3.5-122B 的 7.5 倍,同时保持精度持平甚至更优。
- 论文:Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
- 代码:NVIDIA-NeMo/Nemotron
2. 背景
当前 MoE 大语言模型虽然在固定推理代价下能取得更高精度,但仍存在以下不足:
- 内存带宽瓶颈:在低延迟服务场景中,MoE 推理的主要开销来自读取专家权重,每个专家矩阵大小为 ( 为隐藏维度, 为专家 FFN 中间维度),开销随维度线性增长
- 通信瓶颈:在吞吐导向的服务场景中,分布式 MoE 推理的 all-to-all 路由通信量与 成正比( 为激活专家数),通信开销随维度和激活专家数增长
- 现有 MoE 设计缺乏软硬件协同优化:大多数 MoE 设计仅从高层稀疏性论证出发,面向离线吞吐场景优化,没有充分考虑在线部署的延迟、内存带宽和通信约束
- 推理效率与精度的矛盾:标准 Transformer 的 KV Cache 随序列长度二次增长,长上下文推理的内存开销巨大
基于上述问题,Nemotron 3 Super 从软硬件协同设计的角度重新审视 MoE 架构,提出了 LatentMoE,并结合 Hybrid Mamba-Attention 架构来解决推理效率问题。
3. 框架
3.1 整体架构
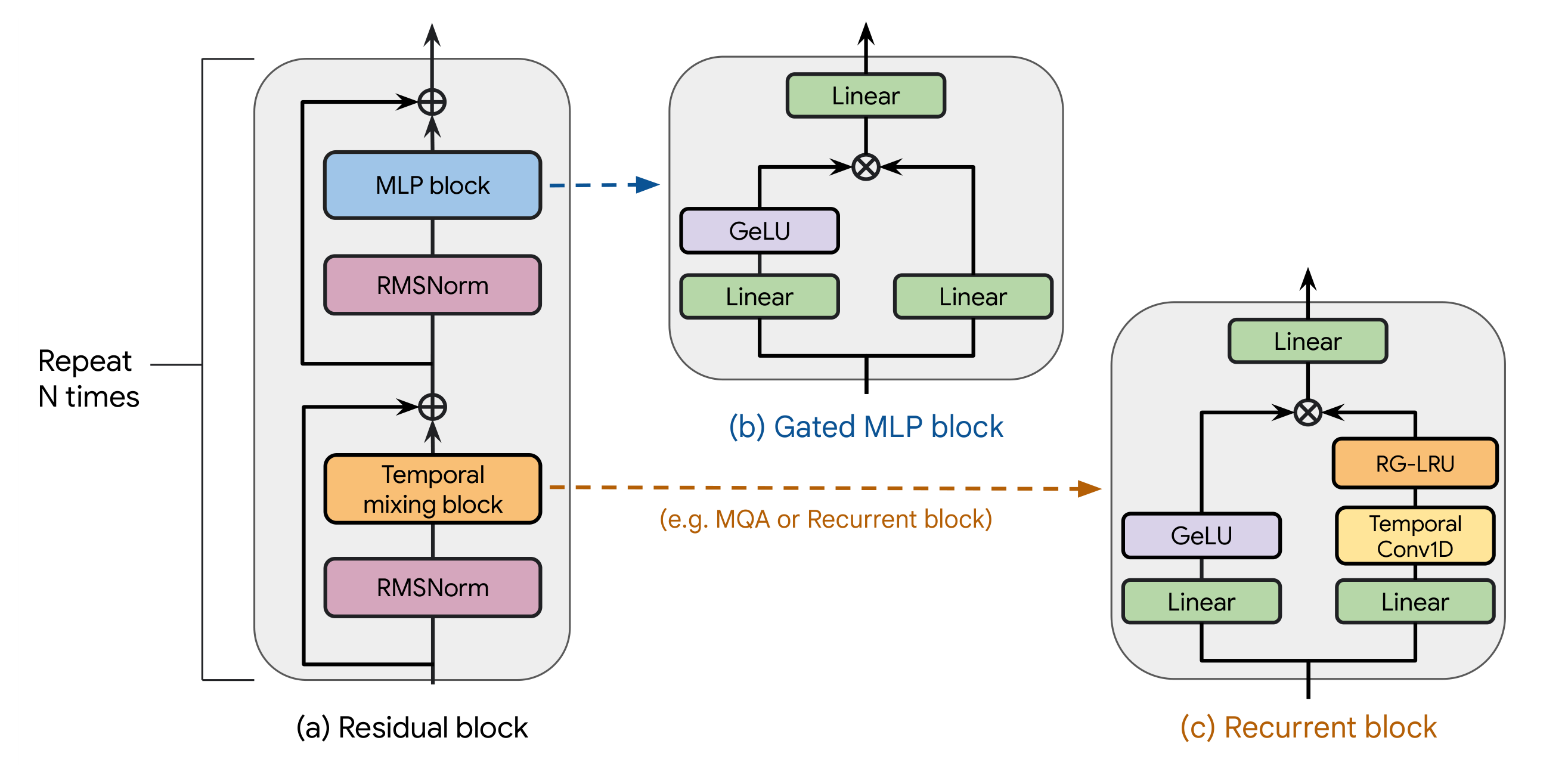
Nemotron 3 Super 的整体架构延续了 Nemotron 3 Nano 的混合设计思路,扩展到 120.6B 总参数、12.7B 激活参数。模型由三个核心组件构成:LatentMoE 稀疏扩展、MTP 推理加速层、以及周期性混合 Mamba-Attention 交替模式。
核心架构参数如下:
| 配置 | Nemotron 3 Super 120B-A12B Base |
|---|---|
| 总层数 | 88 |
| 模型维度 | 4096 |
| Q-Heads | 32 |
| KV-Heads | 2 |
| Head 维度 | 128 |
| Mamba 状态维度 | 128 |
| Mamba Groups | 8 |
| Mamba Heads | 128 |
| Mamba Head 维度 | 64 |
| 专家隐藏维度 | 2688 |
| 共享专家中间维度 | 5376 |
| 每层总专家数 | 512 |
| Top-K(激活专家数) | 22 |
| MoE 隐空间维度 | 1024 |
| MTP 层数(共享权重) | 2 |
88 层网络按周期性模式交替排列 Mamba-2 块与 MoE 层,其中少量 Self-Attention 层作为"全局锚点"插入,实现全 token 交互和长程信息路由。Mamba-2 块在生成时使用常数大小的状态,大幅减少内存开销和延迟。
3.2 LatentMoE
LatentMoE 是本文最重要的架构创新。其核心思想是将 MoE 的路由和专家计算从原始隐藏维度 投影到更低的隐空间维度 中执行。
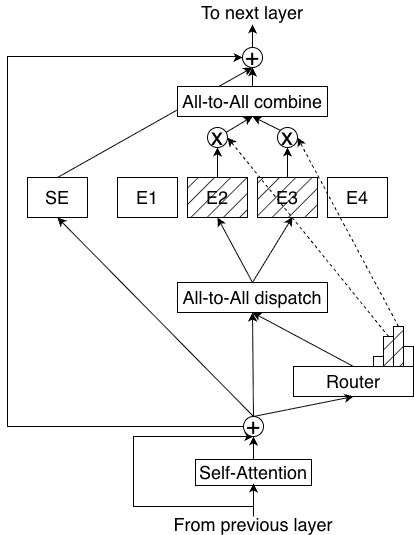
具体流程:每个输入 token 首先通过可学习的下投影矩阵 投影到低维隐空间 ,压缩后的表示在隐空间中被路由到扩展的专家集中进行计算。计算完成后,输出通过可学习的上投影矩阵 投影回维度 。
这一设计基于五条从软硬件协同分析中得出的原则:
- 低延迟场景下,MoE 推理受限于专家权重的内存带宽读取开销,需要减小 或
- 吞吐场景下,分布式 MoE 受限于 all-to-all 路由通信量(),需要减小 或
- 保持模型质量需要保持有效非线性预算 不变
- 任务的有效特征秩 给出了 可缩减的下界
- 增加总专家数 和 top- 可提升质量
通过将计算移入隐空间,每个专家的权重读取量和 all-to-all 通信量都降低了 倍。节省下来的资源用于将总专家数从 增加到 ,激活专家数从 增加到 。维度降低抵消了专家数量增加的开销,在相似的计算和通信预算下获得更高的模型质量。非路由计算(门控网络、共享专家、非专家层)仍在完整维度 中执行。
3.3 Multi-Token Prediction (MTP)
Nemotron 3 Super 引入了 MTP 目标函数,同时提升建模质量和推理效率。不同于传统的 next-token 训练,MTP 优化模型在每个位置预测多个未来 token,鼓励表征捕获多步依赖和长程结构。
在推理阶段,辅助预测头充当内置的 draft 模型,生成候选续写,由主模型在单次前向传播中验证。这大幅降低了解码延迟,且额外 FLOPs 远少于使用外部 draft 模型。
共享权重设计:标准 MTP 使用 个独立 head 分别预测固定偏移量(如 ),但复用固定偏移 head 进行自回归生成会存在训练-推理不匹配——训练时基于 ground truth 隐状态,推理时基于自身生成的隐状态。Nemotron 3 Super 通过在多个 MTP head 之间共享参数来解决这一问题,使得统一的预测头暴露于多个偏移量,增强了自回归生成中对自身隐状态的鲁棒性。同一个 head 可以在推理时递归应用,生成更长的 draft 序列。
3.4 预训练策略
预训练分为两个阶段:
- 阶段一(80%,20T tokens):关注数据多样性和广泛覆盖
- 阶段二(20%,5T tokens):关注高质量数据和 benchmark 精度
整个预训练过程在 NVFP4 精度下完成,是首个在 FP4 精度下完成大规模预训练的模型。长上下文扩展支持到 100 万 token。
3.5 后训练
后训练重点关注 Agentic 能力。通过大幅扩展 RL 环境的广度、Agentic 训练数据的数量和质量,以及多步工具使用行为的训练量来增强模型的 Agent 能力。为了有效训练多样化的长 horizon 任务,改进了 RL 基础设施,实现了大规模异步训练。
3.6 量化:NVFP4 与 AutoQuantize
模型使用 NVFP4 格式进行量化和部署。NVFP4 采用双尺度方案:per-tensor 的全局缩放因子和 per-block 的细粒度缩放因子。
AutoQuantize 算法:通过二阶敏感性度量来为每个算子选择最优量化格式。对每个算子 和格式 ,计算敏感性:
其中 是局部 Hessian 近似。由于完整 Hessian 计算代价高昂,采用对角 Fisher 信息矩阵近似:
其中 ,。
AutoQuantize 求解约束优化:
其中 为部署代价(FLOPs), 为总预算。算法还考虑了线性层融合约束(QKV 共享格式)和 MoE 层约束(同层所有稀疏专家共享格式)。
4. 实验
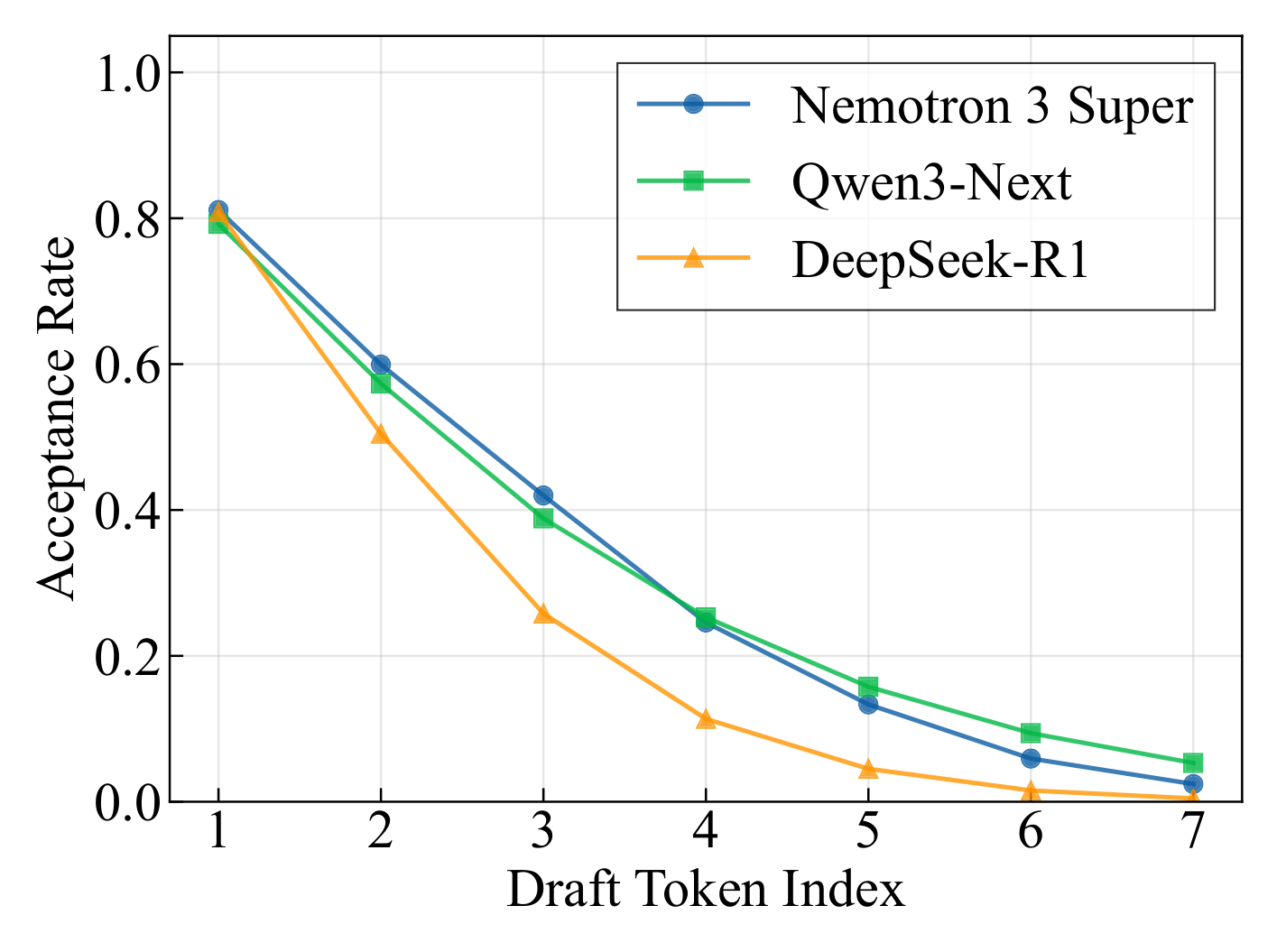
4.1 MTP 推测解码性能
在 SPEED-Bench 上评估 MTP 的平均接受长度(draft 长度 = 7):
| 类别 | DeepSeek-R1 | Qwen3-Next | Nemotron 3 Super |
|---|---|---|---|
| Coding | 2.99 | 4.32 | 3.78 |
| Humanities | 2.67 | 3.07 | 3.26 |
| Math | 2.98 | 3.89 | 3.73 |
| Multilingual | 2.83 | 3.97 | 4.05 |
| QA | 2.63 | 3.09 | 3.16 |
| RAG | 2.79 | 3.53 | 3.78 |
| Reasoning | 2.80 | 3.47 | 3.59 |
| Roleplay | 2.19 | 2.17 | 2.82 |
| STEM | 2.79 | 3.37 | 3.30 |
| Summarization | 2.59 | 3.06 | 3.48 |
| Writing | 2.41 | 2.69 | 2.99 |
| Average | 2.70 | 3.33 | 3.45 |
发现:
- Nemotron 3 Super 的总体平均接受长度(3.45)超过 DeepSeek-R1(2.70)和 Qwen3-Next(3.33)
- 在多语言(4.05)和摘要(3.48)任务上表现尤为突出
- 在所有类别中均优于 DeepSeek-R1,在大部分类别上与 Qwen3-Next 竞争或更优
- 共享权重的自回归设计在更长 draft 深度(位置 4-7)上表现出更稳定的接受率
4.2 量化算法消融
对比不同 PTQ 算法在 NVFP4 量化下的精度表现:
| 算法 | MMLU-Pro | GPQA | LiveCodeBench | AA-LCR |
|---|---|---|---|---|
| BF16(无量化) | 83.49 | 79.92 | 72.91 | 53.00 |
| Default NVFP4 PTQ | 82.99 | 79.29 | 70.18 | 55.50 |
| Weight per-block MSE | 83.31 | 79.92 | 71.37 | 56.75 |
| Weight per-block output MSE | 83.05 | 78.98 | 71.00 | 57.06 |
| GPTQ | 83.11 | 80.05 | 69.79 | 57.87 |
发现:
- NVFP4 量化带来的精度损失非常小,Weight per-block MSE 方法在 MMLU-Pro 上仅损失 0.18 分
- GPTQ 在 GPQA 上甚至超过 BF16 基线(80.05 vs 79.92),说明量化噪声在部分任务上可能起到正则化效果
- 量化模型在 AA-LCR 指标上反而优于 BF16,所有量化方法的 AA-LCR 均高于 BF16 的 53.00
4.3 与 SOTA 模型对比
在主要 benchmark 上的精度和吞吐量对比:
| Benchmark | Nemotron 3 Super (BF16) | Nemotron 3 Super (NVFP4) | GPT-OSS-120B | Qwen3.5-122B |
|---|---|---|---|---|
| IFBench (指令遵循) | 72.6 | 73.3 | - | 73.8 |
| HMMT Feb25 (数学) | 94.7 | 95.4 | - | 91.4 |
| SWE-Bench (编码) | 60.5 | 59.9 | - | 66.4 |
| HLE (科学) | 18.3 | 17.4 | - | 25.3 |
| Term Bench Hard (终端) | 22.8 | 24.5 | - | 26.8 |
| Tau Bench v2 (工具) | 25.8 | 60.5 | - | 74.5 |
| RULER @ 1M (长上下文) | 61.1 | 61.0 | - | 22.3 |
| 相对吞吐量 | 2.2 | 2.2 | 1.0 | 0.3 |
发现:
- 在推理吞吐量方面,Nemotron 3 Super(NVFP4)分别达到 GPT-OSS-120B 的 2.2 倍和 Qwen3.5-122B 的 7.5 倍
- 在 RULER @ 1M 长上下文评测中,Nemotron 3 Super 达到 61.0+,远超 Qwen3.5-122B 的 22.3,体现了 Hybrid Mamba 架构在长上下文上的优势
- NVFP4 量化对精度的影响极小,部分 benchmark 上量化后甚至略优
- 在 SWE-Bench 等编码任务上与竞品持平或略低,但在数学推理(HMMT 95.4)上显著领先
4.4 预训练 Checkpoint Merge 效果
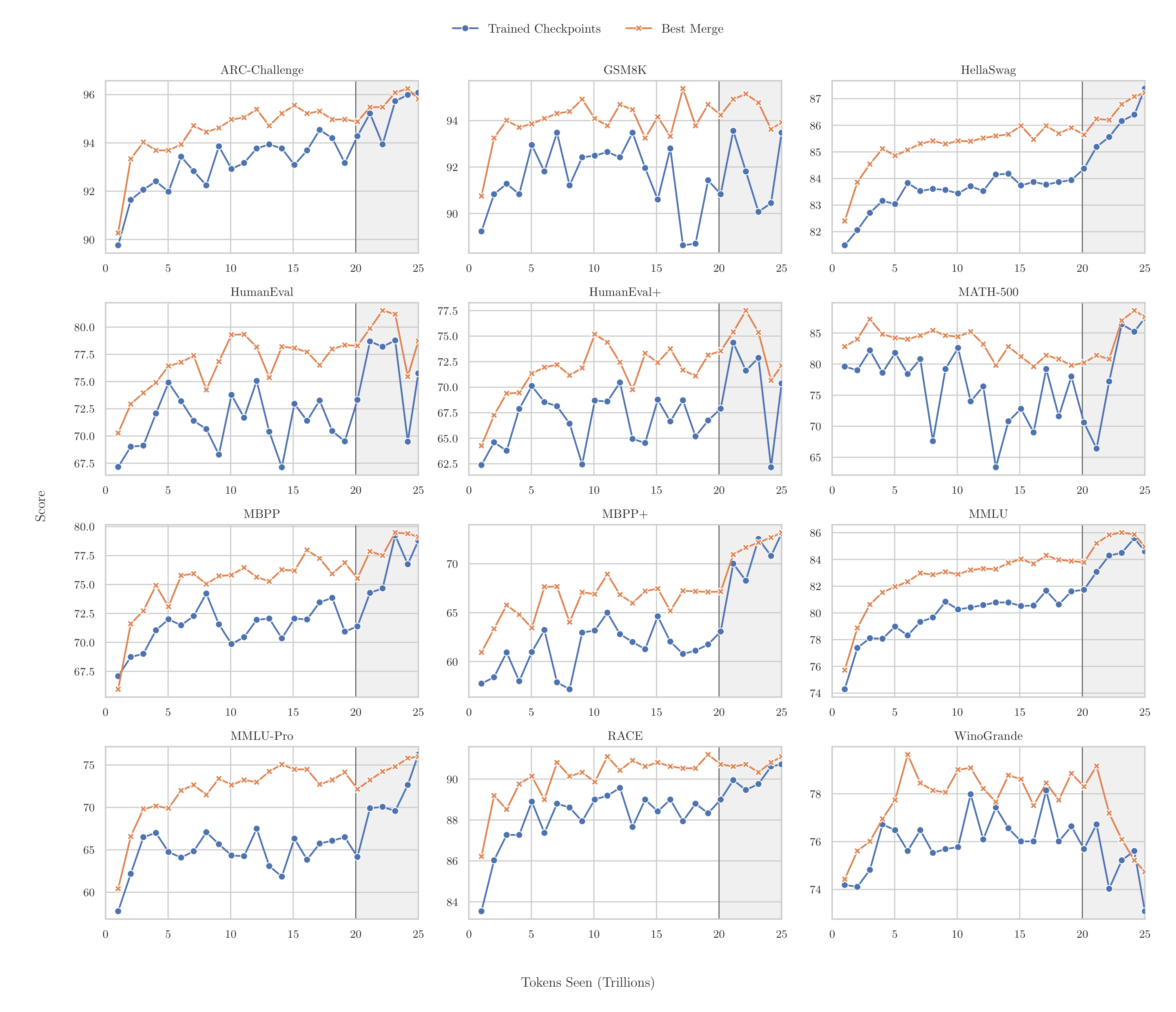
通过离线 checkpoint merge 策略,在 12 个 benchmark 上均超过了训练过程中任意单个 checkpoint 的精度。图中展示了从预训练初期到 25T token 完成时各 benchmark 的精度变化曲线,虚线为最佳 merge 结果。Merge 策略在 LR 衰减阶段(阴影区域)的 checkpoint 上尤其有效,能在所有任务类型上实现一致的精度提升。
5. 总结
Nemotron 3 Super 展示了几个值得关注的工程实践:
- FP4 预训练的可行性:首次在大规模模型上验证了 NVFP4 预训练的稳定性,为未来更低精度训练铺路
- LatentMoE 的设计思路:从软硬件协同角度出发,将维度降低的资源节省转化为更多专家和更高 top-K,在相同推理预算下获得更好的模型质量
- 共享权重 MTP:通过权重共享解决训练-推理分布不匹配问题,使自回归推测解码在更长 draft 长度上保持稳定
模型的局限在于部分 benchmark(如 HLE、Tau Bench)与 Qwen3.5-122B 仍有差距,Agentic 能力还有进一步提升空间。同时,LatentMoE 引入的投影层也带来了一定的额外参数和计算开销。