Attention Residuals
1. 前言
现代大语言模型普遍采用 PreNorm 残差连接,但这种固定权重的累加方式会导致隐藏状态随深度无控增长,逐渐稀释早期层的贡献。作者观察到了深度维度的信息聚合与 RNN 在序列维度的循环聚合之间存在对偶性,从而提出了 Attention Residuals (AttnRes)。
核心思路是:将标准残差连接中的固定单位权重累加,替换为基于 softmax 的注意力加权聚合。每一层通过一个可学习的伪查询向量 ,对前面所有层的输出计算注意力权重,实现内容感知的选择性特征聚合。为了降低大模型训练时的显存和通信开销,论文进一步提出了 Block AttnRes,将层分组为块,仅在块级表示上应用注意力。在 48B 参数模型的实验中,AttnRes 有效缓解了 PreNorm 的稀释问题,使输出幅度保持有界,梯度分布更均匀,并在所有下游任务上取得了性能提升。
2. 背景
标准残差连接的更新规则为 。展开递推式后,第 层的隐藏状态是 embedding 和所有前层输出的等权求和:。
这种固定权重的累加存在几个根本性限制:
- 无选择性访问:不同类型的层(如 attention 和 MLP)接收到相同的聚合状态,无法根据需要加权
- 不可逆的信息损失:通过聚合丢失的信息无法在更深层被选择性地恢复
- 输出增长:在 PreNorm 下,隐藏状态幅度随深度呈 增长,每层的相对贡献被稀释,迫使更深层产生越来越大的输出来获得影响力
现有的改进方法如 Highway Networks 引入了可学习的门控,但仍然只能访问紧邻的前一层状态 ,这是一个压缩了所有早期层信息的单一状态。这启发了作者:序列建模中 Transformer 用注意力替代 RNN 的递归,解决了类似的瓶颈;那么在深度维度上,是否也能用注意力替代残差的固定累加?
3. 框架
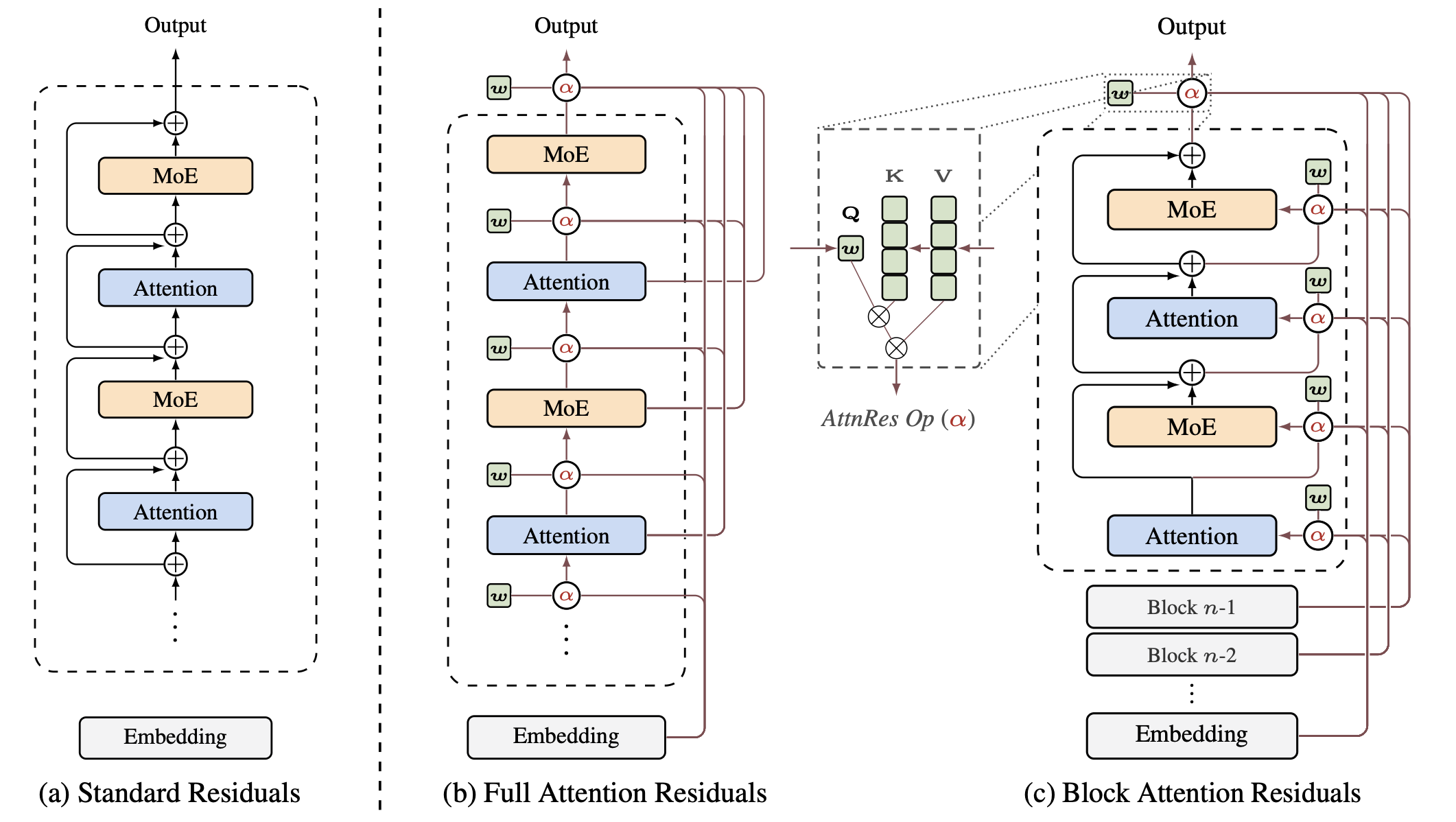
3.1 Full Attention Residuals
AttnRes 的核心思想是将深度维度的信息聚合从固定累加转变为基于 softmax 的注意力聚合。对于第 层,其输入通过对所有前层输出进行注意力加权求和得到:
其中注意力权重 通过 softmax 计算得到:
这里 ,查询向量和键值向量的定义为:
其中 是每层独立的可学习伪查询向量,与层的 forward 计算解耦。RMSNorm 的作用是防止输出幅度大的层主导注意力权重。这种设计使得标准残差连接和基于递归的变体都可以被统一视为深度维度的线性注意力,而 AttnRes 将其推广到了深度维度的 softmax 注意力。
3.2 Block Attention Residuals
Full AttnRes 需要在每层访问所有前层输出,在大规模模型训练中,由于激活重计算和流水线并行的使用,这会带来 的显存和通信开销。Block AttnRes 将 层划分为 个块,每块包含 层。
块内累加:块内层输出通过标准残差求和压缩为单一表示:
块间注意力:仅在 个块级表示上应用完整的注意力机制。对于块 中第 层,值矩阵为:
其中 为 token embedding, 为当前块内的部分和。这使得显存和通信开销从 降低到 。块数 控制着插值的两个极端: 恢复为 Full AttnRes, 则退化为标准残差连接。实验表明 即可恢复大部分收益。
3.3 基础设施优化
为使 Block AttnRes 在大规模训练和推理中实际可用,作者设计了多项系统优化:
- 跨阶段缓存:在流水线并行中,每个 rank 缓存已接收的块表示,阶段间只传输增量块而非完整历史,避免冗余传输
- 两阶段推理:利用伪查询 与输入无关的特性,将推理分为批处理的块间注意力计算和顺序的块内依赖处理,通过 online softmax 合并结果,将每层的 I/O 从 降低到
4. 实验
4.1 Scaling Law 实验
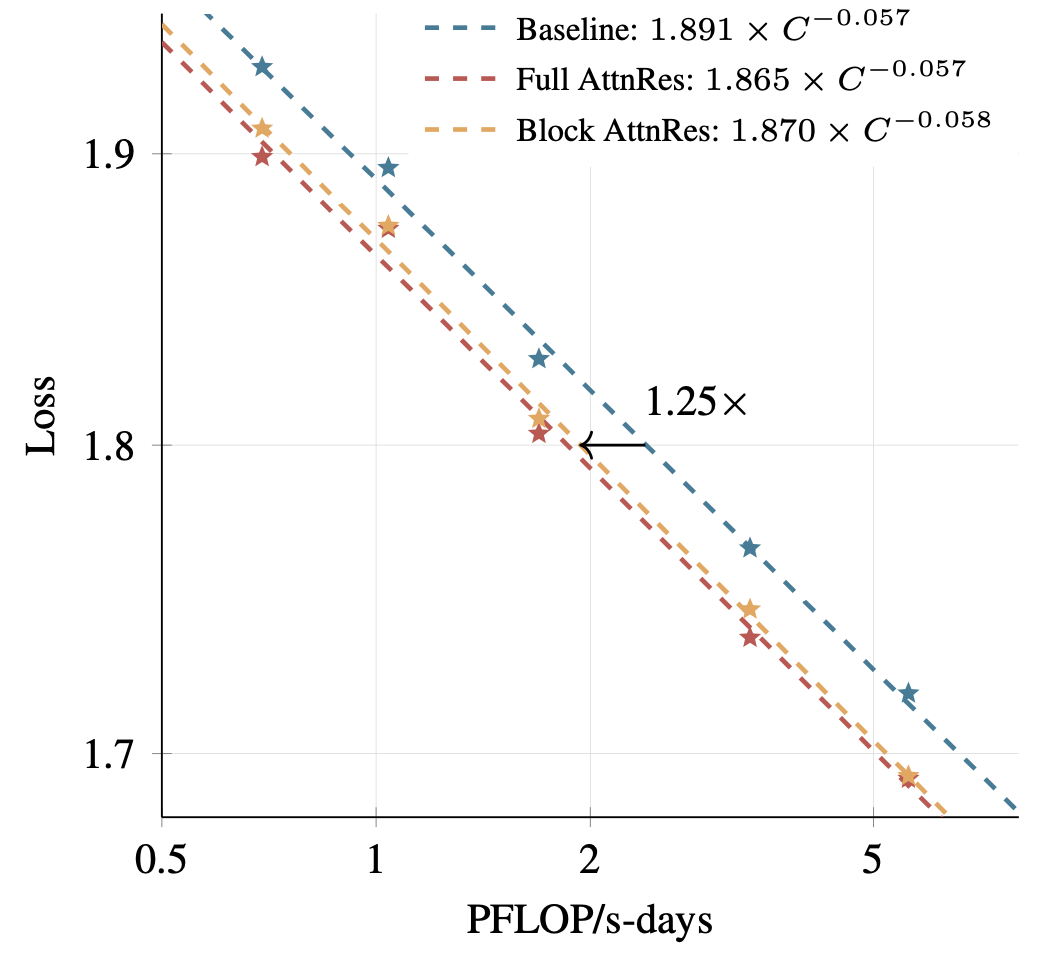
AttnRes 在不同计算预算下一致优于标准残差基线。Block AttnRes 的性能可以匹配使用 1.25 倍计算量训练的基线模型,说明其具有显著的计算效率优势。
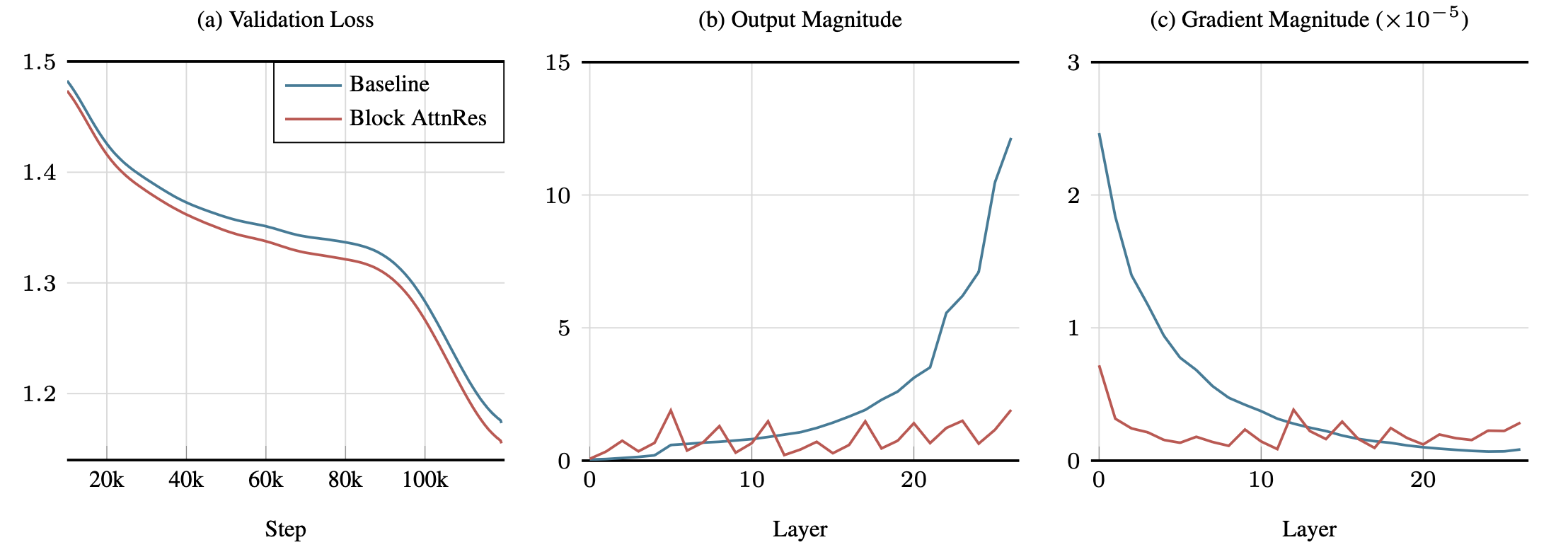
4.2 训练动态分析
| 指标 | 标准 Residual | AttnRes |
|---|---|---|
| 隐藏状态幅度随深度变化 | O(L) 无控增长 | 保持有界 |
| 梯度范数跨层分布 | 不均匀,深层梯度偏大 | 更均匀分布 |
| 早期层贡献 | 被逐渐稀释 | 可选择性检索 |
| 有效深度利用 | 部分层可被剪枝 | 各层贡献更均衡 |
- AttnRes 有效缓解了 PreNorm 导致的幅度增长问题,使各层输出幅度在深度方向上保持稳定
- 梯度在深度方向上分布更均匀,有利于更深网络的稳定训练
- 早期层信息不再被淹没,而是可以通过注意力权重被选择性地检索
4.3 开销分析
| 场景 | 开销指标 | 数值 |
|---|---|---|
| 训练 | 额外计算开销 | 极小 |
| 推理 | 延迟开销 | < 2% |
| 显存 | Block AttnRes 存储 | 每token仅8个隐藏状态 () |
| 通信 | 跨阶段传输量 | 从 降至 |
4.4 下游任务评测
在 48B 总参数 / 3B 激活参数的 Kimi Linear 架构上,使用 1.4T tokens 预训练后,AttnRes 在所有评测的下游任务上均取得了性能提升,验证了其实际有效性。
5. 总结
AttnRes 从序列与深度的对偶性出发,将 Transformer 在序列维度上从线性到 softmax 的演进映射到深度维度,用可学习的注意力权重替代残差连接中的固定累加。Block AttnRes 通过块级划分将开销从 降低到 ,配合跨阶段缓存和两阶段推理策略,使其在大规模模型训练中几乎无额外开销。该方法在 48B 参数模型上的实验全面验证了其有效性和实用性。