Attention Residuals
前言
现代 LLM 中的残差连接配合 PreNorm 已经成为标准配置,但它们以固定权重累加所有层的输出。这种均匀聚合导致隐藏状态随深度增长,逐渐稀释每层的贡献。作者提出了 Attention Residuals(AttnRes),用 softmax 注意力替代固定累加,让每一层能以可学习的、依赖于输入的权重选择性地聚合前层表示。
针对大规模训练中全量 AttnRes 的显存和通信开销问题,进一步提出了 Block AttnRes,将层分组为块并在块级表示上做注意力,把开销从 降到 。结合跨阶段缓存和两阶段计算策略,Block AttnRes 成为一个实际可用的标准残差替代方案,训练开销极小,推理延迟增加不到 2%。
背景
标准残差连接的更新规则是 ,展开后每层接收的是所有前层输出的等权累加。这种固定权重方式存在几个根本性限制:
- 无选择性访问:不同类型的层(如 attention vs. MLP)接收相同的聚合状态,但它们可能需要不同的历史信息加权
- 不可逆信息损失:聚合过程中丢失的信息无法在更深层被选择性地恢复
- 输出增长:更深层需要产生越来越大的输出才能对累积残差产生影响,导致训练不稳定
PreNorm 范式下,隐藏状态幅度随深度以 增长,每层的相对贡献被持续稀释,早期层信息被埋没。已有方法如 scaled residual paths、Highway Networks、Hyper-Connections 等仍然受限于加性递归结构,每一层只能访问其直接前驱的压缩状态。
作者观察到深度维度的累加和 RNN 在序列维度上的递归存在形式上的对偶性。Transformer 正是通过用注意力替代序列递归解决了 RNN 的瓶颈——同理,也可以在深度维度上用 softmax 注意力替代固定累加。
框架
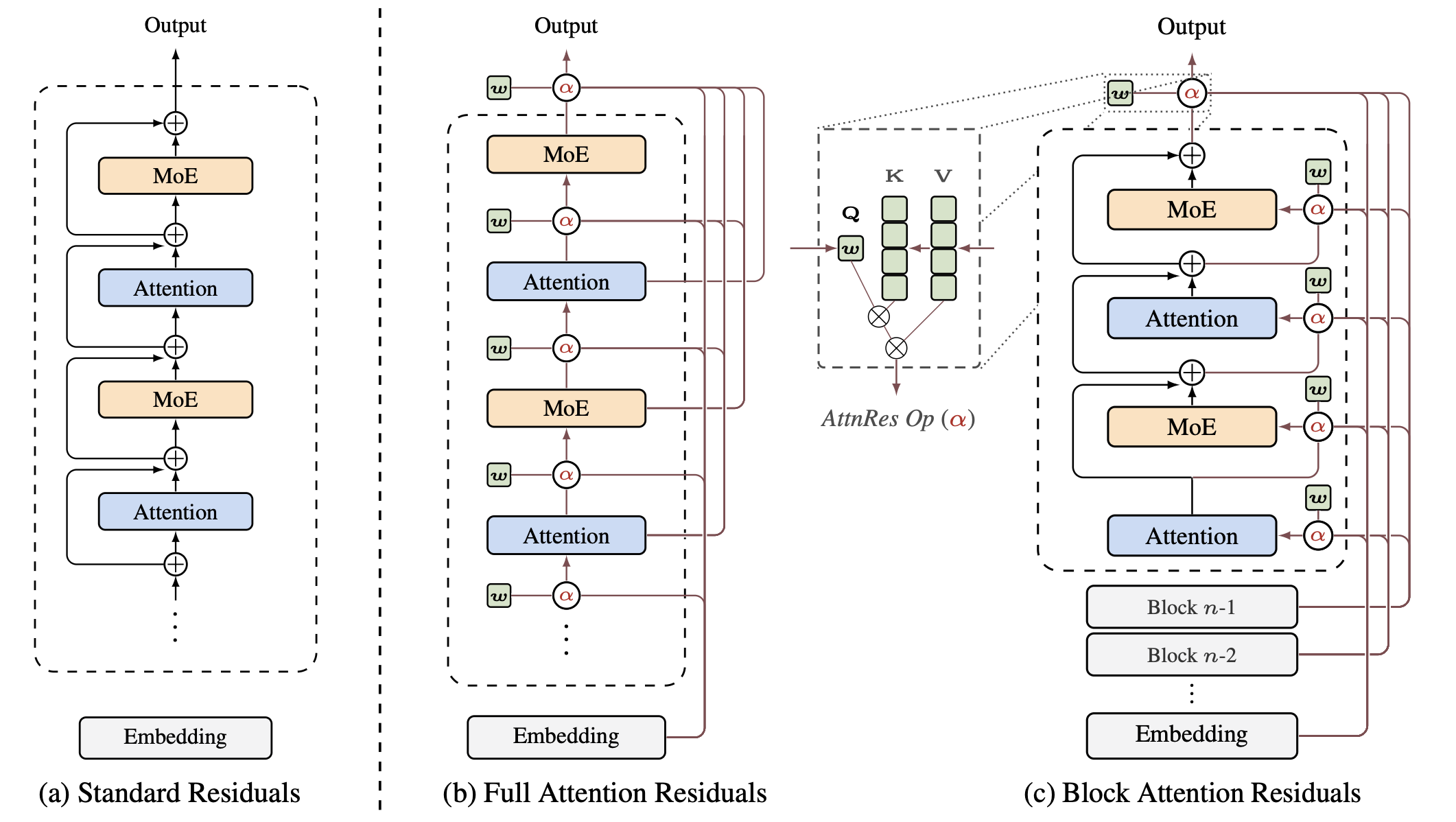
Full Attention Residuals
核心思想是把固定累加 替换为加权聚合 ,其中 是 softmax 注意力权重:
其中核函数 ,query 和 key/value 定义为:
这里 是每层的一个可学习伪查询向量,与层的 forward 计算解耦。RMSNorm 防止大幅度输出的层主导注意力权重。第 层的输入为:
Full AttnRes 的开销:计算 ,显存 。由于深度远小于序列长度,计算开销是可控的。在标准训练中, 的显存与反向传播已保留的激活完全重叠,不引入额外显存。
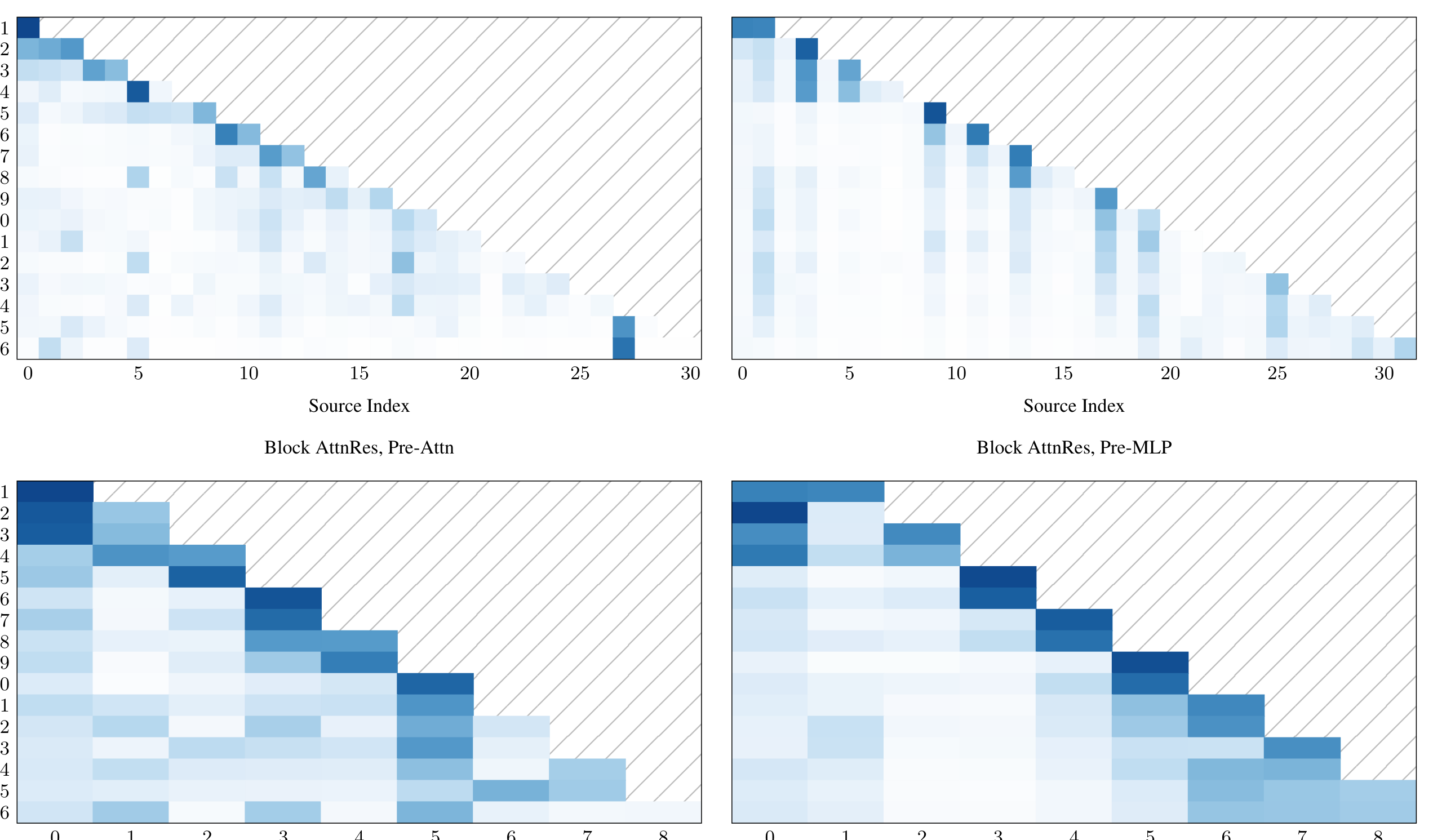
Block Attention Residuals
在大规模训练中,激活重计算和流水线并行被广泛使用,此时所有前层输出必须显式保存并跨阶段传输,通信开销变为 。Block AttnRes 将 层分为 个大小为 的块来解决这一问题。
块内累加:在每个块内,层输出通过求和归约为单一表示:
块间注意力:跨块时,只对 个块级表示和 token embedding 做 softmax 注意力。对于块 中第 层,value 矩阵为:
其中 为 token embedding, 为当前块内的部分和。
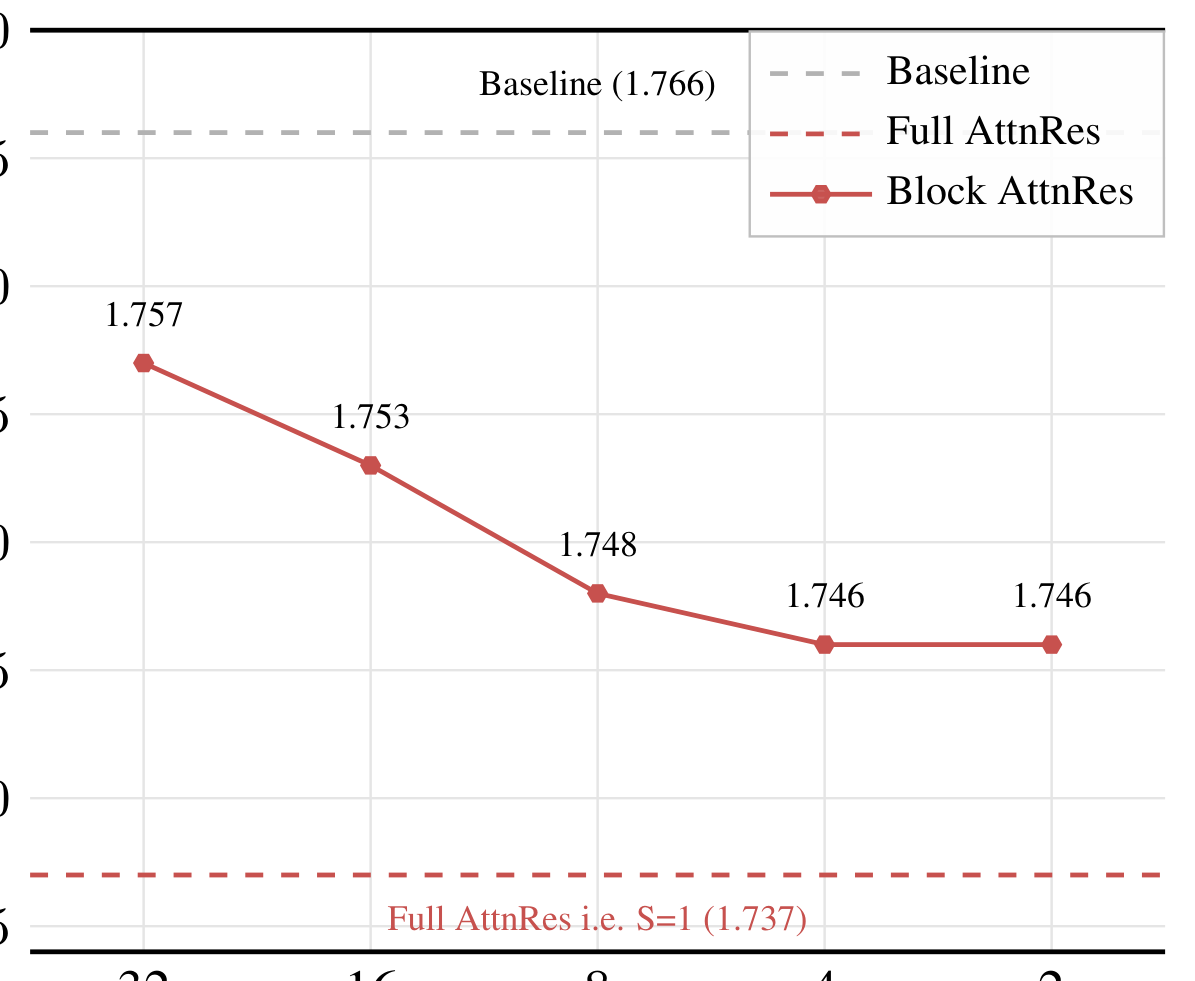
Block AttnRes 将显存和通信从 降到 。 插值于两个极端: 恢复 Full AttnRes, 退化为标准残差连接。实验表明 即可恢复大部分增益。
系统优化
训练阶段——跨阶段缓存:在流水线并行下,每个 rank 缓存已接收的块表示,阶段转换时只传输增量块而非完整历史,避免冗余传输。
推理阶段——两阶段计算:利用伪查询 与输入无关的特性,将推理分为两个阶段:Phase 1 批量计算块间注意力(所有层的查询共享前块的 key-value),Phase 2 顺序处理块内依赖。这使每层 I/O 从 降到 。结合 online softmax 实现精确等价。
实验
Scaling Law
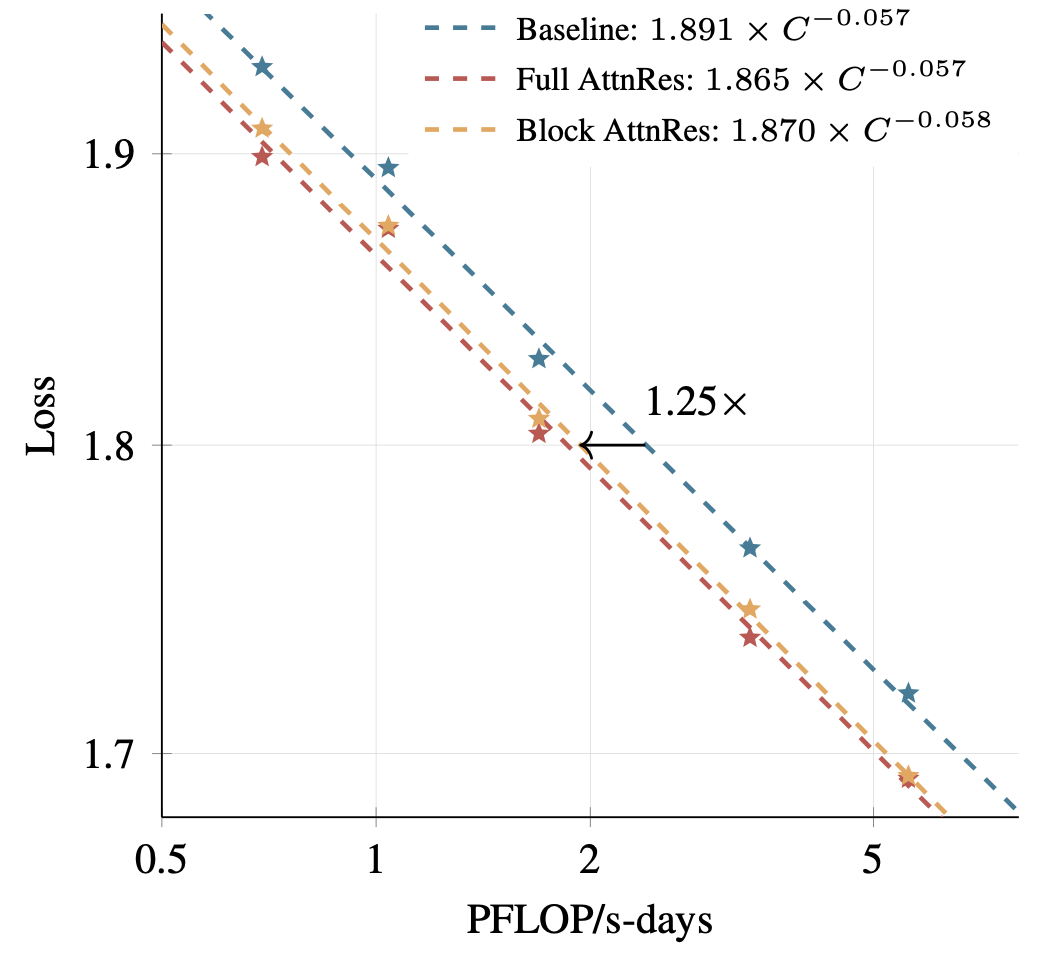
Scaling law 实验证实 AttnRes 在不同计算预算下一致优于基线:
- Block AttnRes 的 loss 与使用 1.25 倍计算量训练的基线模型相当
- 改进在不同模型规模下保持一致,证实了方法的 scaling 能力
- Full AttnRes 略优于 Block AttnRes,但差距随块数增加迅速缩小
消融实验
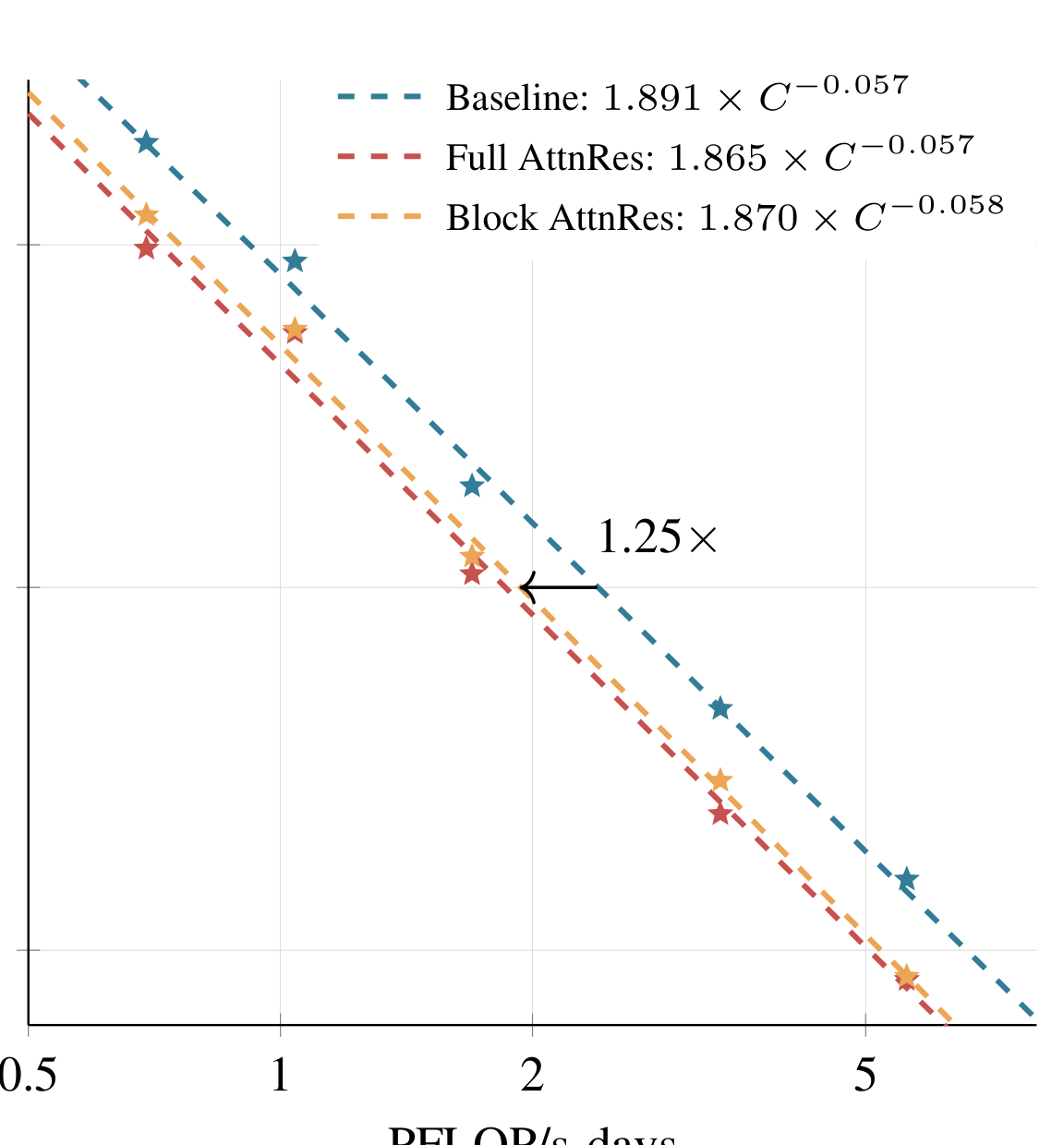
- 块数 即可恢复 Full AttnRes 大部分增益,进一步增加块数收益递减
- 内容依赖的深度选择(softmax 注意力)显著优于固定权重方案
- RMSNorm 在核函数中至关重要,防止大幅度层输出主导注意力分布
- AttnRes 与不同归一化方案(PreNorm、PostNorm 等)正交且兼容
训练动态分析
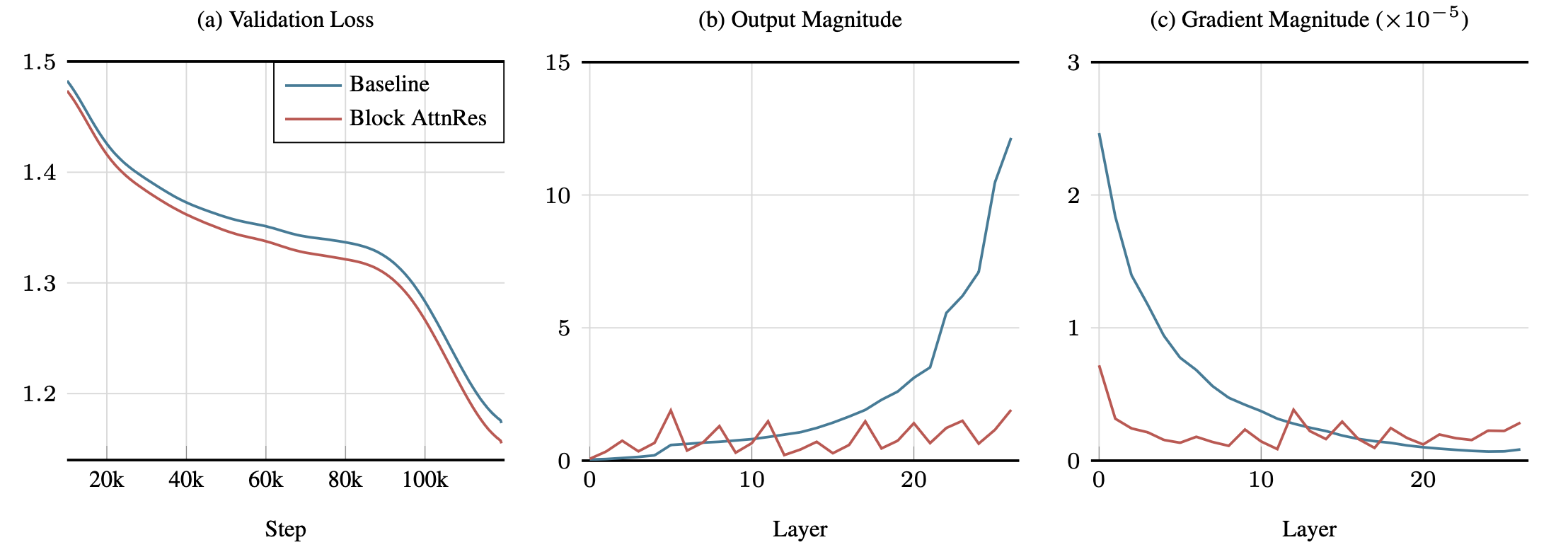
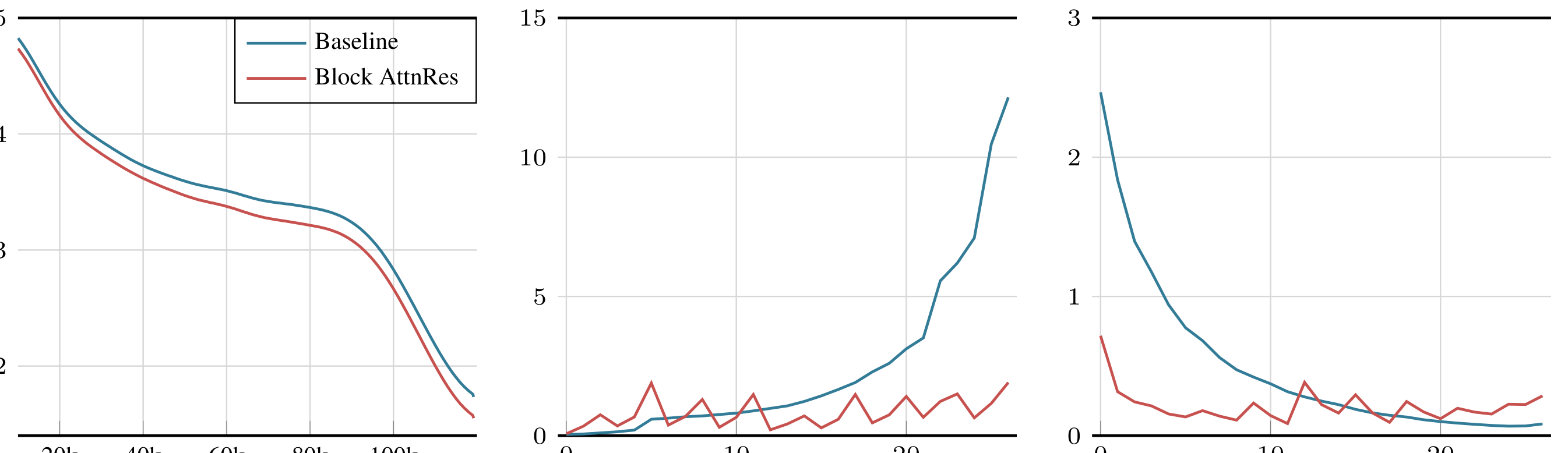
在 48B 总参数 / 3B 激活参数的 Kimi Linear 架构上,使用 1.4T tokens 预训练的分析结果:
- 输出幅度有界:AttnRes 有效缓解了 PreNorm 导致的 幅度增长问题,各深度层的输出幅度保持稳定
- 梯度分布均匀:各层的梯度范数分布更加均匀,避免了深层梯度消失的问题
- 标准残差下深层贡献被严重稀释,而 AttnRes 通过选择性聚合保持了各层的信息贡献
下游任务评估
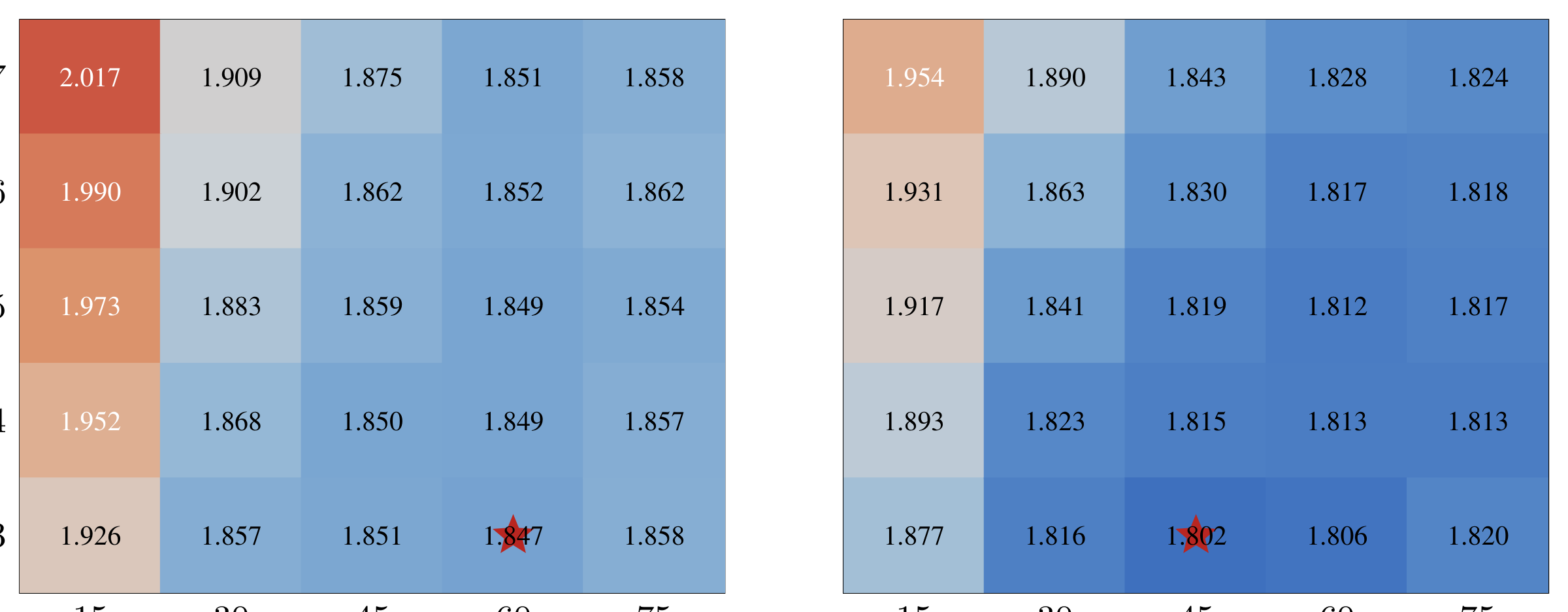
在所有评估的下游基准测试上,AttnRes 模型均取得了一致的性能提升,涵盖知识理解、数学推理、代码生成等多种任务类型。
总结
AttnRes 的核心 insight 在于将序列维度上"从 RNN 到 Transformer"的进化思路平行迁移到深度维度上——标准残差连接本质上是在做深度维度的线性注意力,而 AttnRes 将其升级为 softmax 注意力。Block AttnRes 通过块级聚合在效果和效率之间取得了良好的平衡。随着未来硬件互联的改进,Full AttnRes 的 通信开销可能变得实际可行,进一步释放完整深度注意力的潜力。